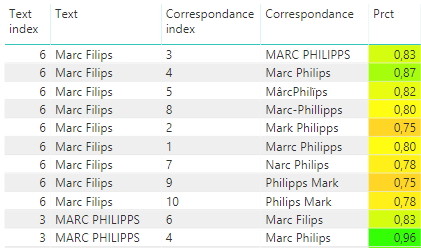
Duplicates detection in Power Query using different methods
As duplicates are a nightmare in databases, I wrote a function to identify them between two tables. Duplicates detection in Power Query is extremely useful for data consistency. Additionally, it helps to avoid relationships isues.
You may also use the same function with only one table. The function is optionally insensitive to case, separators and accents. It uses three methods :
- Power query fuzzy merge (not the best results but fast)
- Cartesian product (provides distance and best results but very slow)
- Ngram (provides distance but very slow)
If some of you have better solutions, I would be glad to know.
How to implement duplicates detection in Power Query
- Download the PBIX file : ‘Data cleansing.pbix’
- Open Power Query
- Copy parameters into your own PBIX file : Fuzzy matching threshold, Duplicates detection method
- Copy functions into your own PBIX file : Fn Cartesian product, Fn Ngram, Fn Duplicates analysis
- Then, call the main function like this (documentation is inside the function) :
#”Fn Duplicates analysis”(Table1 as table, Column1 as text, Index1 as text, Table2 as table, Column2 as text, Index2 as text, Options as text)- Select the method in ‘Duplicates detection method’ parameter
- Select the threshold in ‘Fuzzy matching threshold’ parameter (between 0 and 1)
- Apply changes and refresh the report
I hope this duplicates detection in Power Query will help you. Please share your methods in the comments down below.
Check an other way to find duplicates : Compare the same data from two columns in Power Query

Custom analyser
With ‘Custom analyser’ feature, Power BI Sidetools users can use external tools built by the…
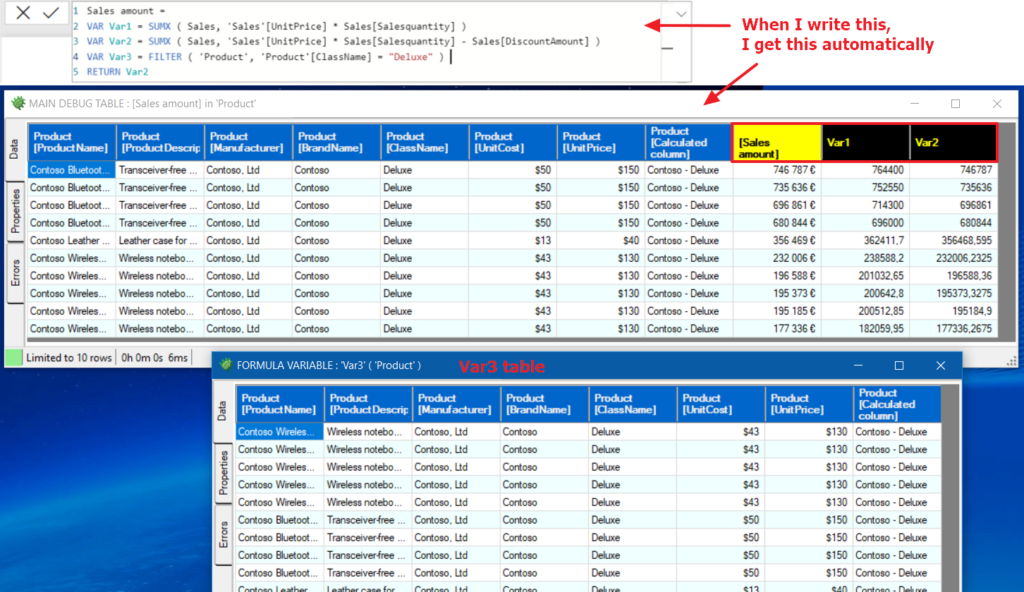
DAX debugger in Power BI Sidetools
DAX debugger is meant to help Power BI report developers displaying sample data from a…
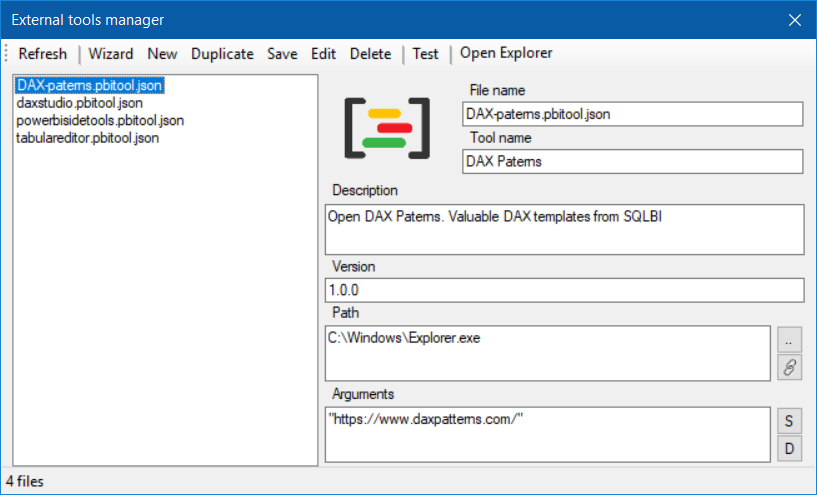
Manage your external tools easily with Power BI Sidetools
Since the Power BI team allowed to launch external tools from the Power BI desktop…

Easily export to Excel with Power BI Sidetools
While working in Power BI desktop, we often need to export to Excel some data…
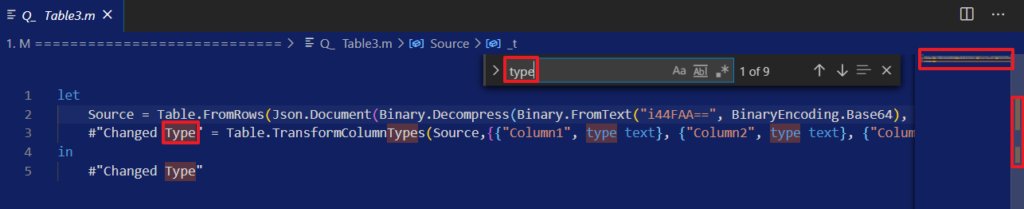
Powerful text and file search in Visual Studio Code
As Power BI Sidetools creates files from your report, you are able to search through…
Compare DAX and M formulas in Visual Studio Code
Compare DAX and M formulas in Visual Studio Code is really easy with the help…